글을 쓰는 시점은 24.04.21으로 Multilingual Diffusion Model에 대한 연구에 관심을 가지고 서칭하고 있다. AltDiffusion: A Multilingual Text-to-Image Diffusion Model이라는 논문을 통해 전반적은 Multilingual Diffusion Model에 대한 사전 연구와 방법, 그리고 왜 Multilingual Diffusion Model을 연구하고 개발하는지를 중점적으로 읽었다. 원래 다국어 디퓨전 모델에 대한 나의 생각은 “굳이? 그냥 번역해서 쓰면 되잖아?”라는 의문이 들었다. 스포를 간단히 하자면 번역툴을 써도 되지만 언어의 문화적, 차이별적인 특성들은 번역으로 하기에 한계가 있다. 또한, 각 언어들의 문화적인 특징을 잘 생성하기 위한 목적으로 다국어 연구가 진행되고 있다고 본 논문에서는 애기하고 있다. 이 글은 다음과 같은 key point를 가지고 논문을 읽고 정리한 내용이다.
- 왜 Multilingual Diffusion Model이 연구되었는가? (번역툴을 이용하는 영어 기반 Diffusion Model과의 차별점)
- CLIP Text Encoder 부분만 학습을 시키는가, 이미지에도 Culture domain을 반영하여 학습시키는가?
- 실험 또는 성능 평가를 어떻게 했는가?
- Limitation
Abstract
- 기존 text-to-image 모델은 언어가 한정적이다.
- 본 논문에서는 새로운 다국어 지원 방식의 18개 언어 지원 모델 개발
- 우선, knowledge distillation 기반 encoder에 다국어 text 학습
- pretrained English-only diffusion model에 연결 후, 학습한다.
- 새로운 벤치마크
- culture-specific concepts을 잘 반영하면서 현존 SOTA T2I model보다 성능 좋다.
Related Work
Multilingual Text-to-image Generation
- SD(Stable Diffusion)은 언어의 한계가 존재한다
- 이런 한계를 극복하기 위해 Taiyi(Wang et al. 2022a) and Japanese SD (Shing and Sawada 2022b)같은 연구 진행되었다.
- 하지만 여전히 언어 다양성 부족함
Multilingual CLIP
- 최근, multilingual CLIP 만들려는 시도 있었다. (Aggarwal and Kale 2020), (Carlsson et al. 2022)
- AltCLIP은 knowledge distillation 기술을 적용시켜 SOTA multilingual CLIP 모델 개발.
Multilingual Image Caption Datasets
- Flickr30k, MS COCO등의 이미지 캡션 데이터셋은 영어로 구성되어 있으며 이는 언어 다양성에 제약이 있다.
- 일부 연구는 다른 언어들에 초점이 맞춰진 이미지 캡션 데이터셋에 초점을 맞춘다.
- Multi30K: German
- Wikimedia Commons: German, French, and Russian
- WIT, XM 3600: multiple languages
- 본 논문에서는 WIT, XM 3600를 바탕으로 MG-18라는 새로운 데이터셋을 구축함.
Method
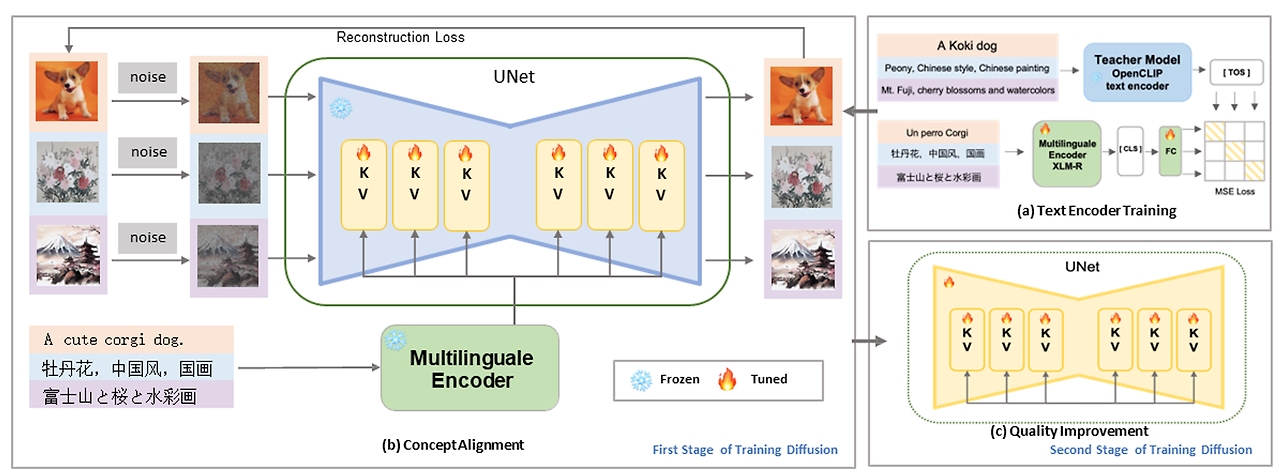
Enhance Language Capability of the Text Encoder

우선, AltCLIP(2022)의 연구가 존재했다. text encoder를 Knowledge Distillation기반으로 18개의 언어를 지원하게 재학습시켰다.
Knowledge Distillation 사용: Text Encoder를 다양한 언어로 확장하기 위해, OpenCLIP의 Text Encoder를 teacher model로, XLM-R을 student model로 사용하여 Knowledge Distillation을 수행. 이 과정은 student model이 teacher model의 언어 능력을 흡수하도록 하여, 18개 언어에 대한 지원을 가능하게 합니다.
teacher model 임베딩과 student model 임베딩의 MSE를 최소화시켜 기존의 OpenCLIP text encoder의 임베딩 공간과 가까운 multilingual text encoder를 얻는 목적이다.
Enhance Language Capability of the UNet
text encoder를 학습 시킨 후, text encoder의 parameters를 고정시키고 기존의 Stable Diffusion을 연결한다. 여기서의 SD는 영어 전용으로 미리 사전 학습된 모델이며 본 논문에서는 SD를 사용했지만 다른 diffusion model을 확장시켜 사용할 수도 있다고 한다. 그런 다음 영어 전용 diffusion model에서 multilingual model로의 변환을 위해 두가지 단계의 학습 방법을 거친다.
Concept Alignment Stage
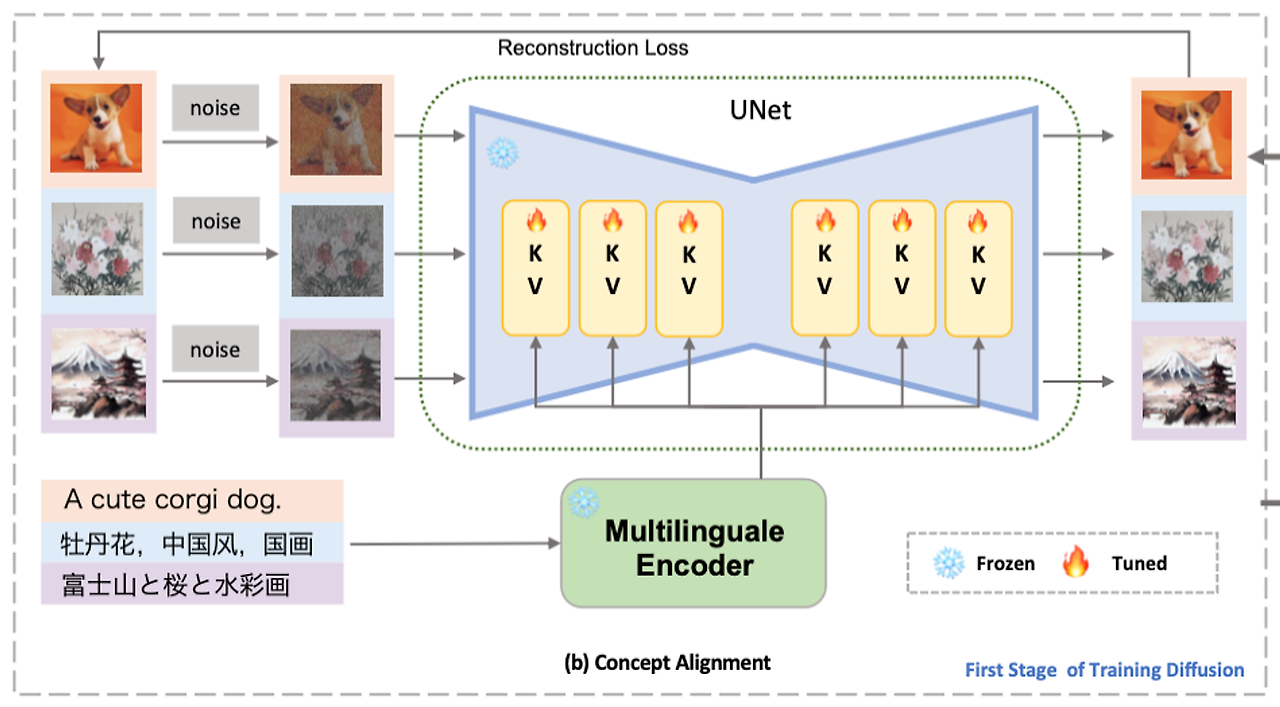
text encoder의 학습 후, text와 이미지 간의 관계를 재학습한다. text encoder와 autoencoder를 고정시키고 denoising diffusion objective를 사용하여 cross-attention의 K,V를 학습시키며 관계를 다시 설정한다.
아래는 denoising diffusion objective의 수식이다.
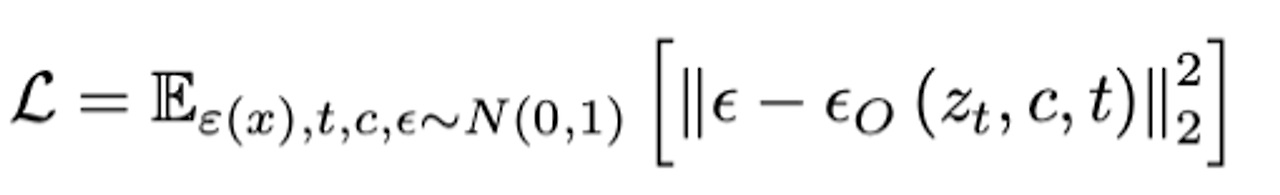
위 단계에서 내가 궁금했던 부분은 다국어 diffusion model을 위해 CLIP을 다국어로 학습되는 것은 이해했는데, 다국어의 이미지 데이터셋으로 이미지 또한 재학습이 되는지가 궁금했다. 이부분의 해답은 학습 데이터 LAION에 있다. 본 논문에서 학습에 사용하는 image-text 데이터셋은 LAION이다. Dataset 섹터를 참조!
Quality Improvement Stage
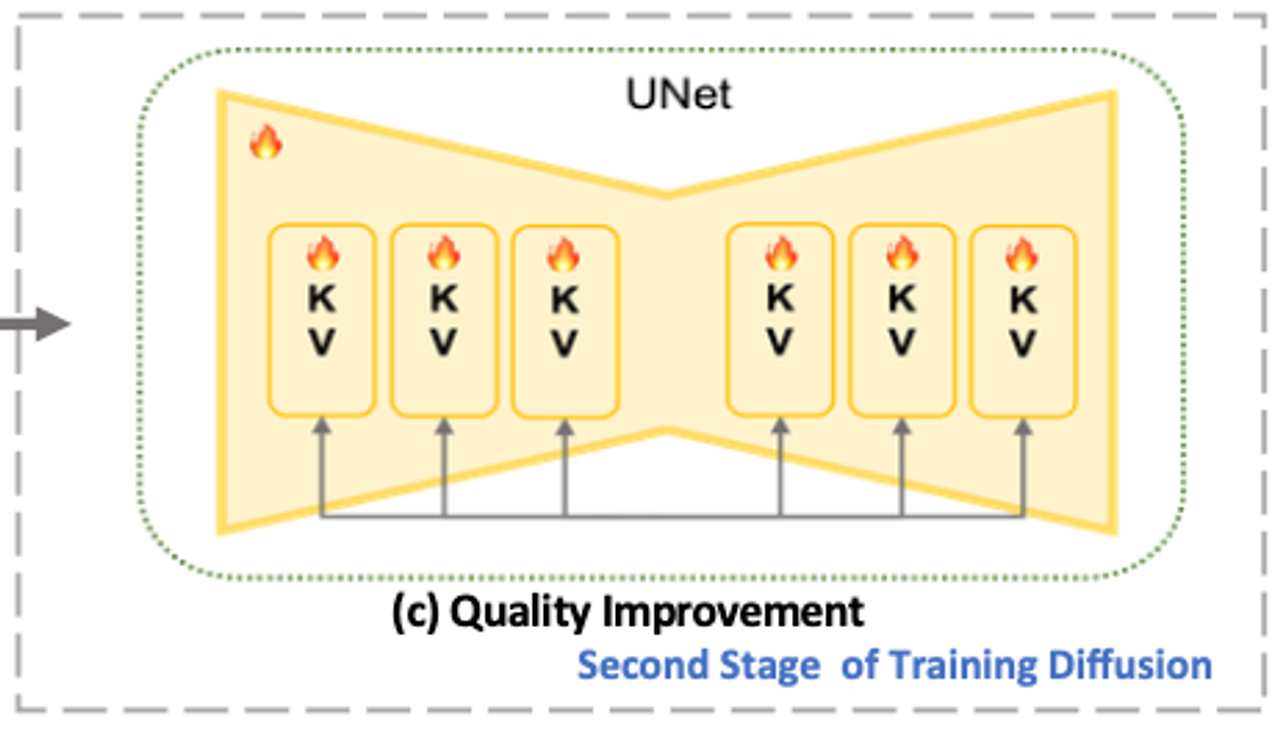
첫 번째 단계에서 얻은 체크포인트를 기반으로, 모든 UNet 파라미터를 fine-tuning한다. 이 단계에서는 더 높은 품질의 이미지를 생성하기 위해 LAION Aesthetics 데이터셋을 사용합니다. 또한, classifier-free guidance 기법을 도입하여 이미지 생성 품질을 더욱 개선합니다.
classifier-free guidance 방법이란?
https://arxiv.org/pdf/2207.12598.pdf
- 10% 텍스트 입력 제거: "SD" 환경에서, 훈련 데이터의 텍스트 입력 중 10%를 무작위로 제거한다.
- 조건부 점수와 비조건부 점수의 조합: 최종 noise 점수 𝜖_𝜃(𝑧𝑡,𝑐,𝑡)ϵ_θ(zt,c,t)는 조건부 점수 𝜖𝜃(𝑧𝑡,𝑐,𝑡)와 비조건부 점수 𝜖𝜃(𝑧𝑡,𝑡)의 조합으로 계산됩니다. 여기서 조건부 점수는 텍스트 입력이 주어진 경우의 모델 출력을 의미하고, 비조건부 점수는 텍스트 입력 없이 모델이 생성한 출력을 의미합니다.
수식: 이 과정은 다음 수식으로 표현됩니다:

여기서 𝛼>1는 조건부 점수에 대한 스케일 가중치이다. 이 수식은 모델이 조건부 데이터(텍스트 입력 포함)와 비조건부 데이터(텍스트 입력 없음)를 어떻게 결합하여 최종 출력을 생성하는지를 정의한다.
Dataset
LAION 5B
LAION 5B 데이터셋은 세 개의 하위 데이터셋으로 구성
- LAION2B-en: 2.32억 개의 영어 이미지-텍스트 쌍을 포함함.
- LAION2B-multi: 2.26억 개의 이미지-텍스트 쌍을 포함하고, 이 텍스트들은 영어를 포함한 100개 이상의 다른 언어들로 이루어져있음.
- LAION1B-nolang
첫번째 학습 단계에서 18개 언어로 된 18억 개의 데이터를 LAION2B-multi에서 필터링하여 LAION2B-en과 결합했다. 즉, 다른 언어가 라벨링 되어있는 이미지 데이터를 학습시켰다는 것이다. 두번째 학습 단계에서는 고품질 LAION 5B를 미적 감각 점수로 필터링한 LAION Aesthetics를 학습시키는데 이 또한, 영어 전용이 아닌 다국어 데이터셋으로 판단해도 될거같다.
즉, 본 논문에서의 다국어 모델은 1차적으로 다국어 기능을 보유하게 하는 text encoder와 다국어 이미지를 학습한 diffusion model인 것이다. text, diffusion 두 단계 모두 다국어 데이터셋을 학습했다.
Evaluation Benchmark
Multilinguale-General-18(MG-18)
- XM 3600에서 WIT로부터 고퀄리티 이미지를 추가함
- 7,000 image-text pairs in 18 languages
- 과도한 텍스트가 포함된 이미지는 T2I 모델의 생성 능력을 평가하기에 부적합하다는 점을 고려하여 5개 이상의 단어가 포함된 이미지를 걸러냄
- AltCLIP를 사용하여 이미지와 캡션 간의 유사도(CLIP SIM)를 계산해 0.2보다 높은 점수만 유지
Multilinguale-Cultural-18(MC-18)
본 논문에서는 multilingual T2I 모델들의 능력중 culture-specific concepts의 이해를 강조한다. culture-specific concepts이란 다른 언어의 그림, 문학, 축제, 음식, 의복, 랜드마크 등의 문화 개념을 의미한다. 이를 평가하기 위해 만든 MC-18를 구축했다고 한다.

우선, 각 언어에서 위 그림의 6개의 측면에서 대표 사례를 선정했다. 그런 다음, ChatGPT를 활용하여 프롬프트를 생성하고 적절한 프롬프트를 사람들이 골랐다. 이 프롬프트는 해당 문화적 개념을 설명하거나 나타낼 수 있는 텍스트일것으로 예상된다.
Experiments
Implement Details
- Optimizer: AdamW
- LR: 1e-4
- 10,000 warmup steps
- 64 NVIDIA A100-SXM4-40GB GPUs
Concept Align Stage
- SD v2.1 512-base-ema를 사용하여 텍스트 인코더 제외 모든 파라미터 초기화
- Batch Size: 3072
- Resolution: 256 x 256
- LAION2B-en과 LAION2B-multi 데이터셋을 사용해 총 330,000 스텝 동안 학습
Quality Improvement Stage
- 330,000 스텝 체크포인트에서 학습을 시작
- Batch Size: 3840
- Resolution: 512 x 512
- 데이터셋 LAION Aesthetics V1-en과 V1-multi를 사용하여 270,000 스텝 학습
- 추가로 270,000 스텝이후 classifier- free guidance learning으로 150,000 스텝 학습
Results on MG-18
실험에서 AD(AltDiffusion)과 비교하는 모델은 SD(Stable Diffusion)인데, 여기서의 SD는 두가지 모델로 비교한다.
1. 프롬프트를 영어에서 다른 언어로 번역한 translation-based SD
2. multilingual baseline diffusion models
모든 인퍼런스 실험 세팅
- resolution은 512 x 512이며,
- 50 DDIM steps,
- 9.0 classifier- free guidance scale
Compare with Translation-based SD v2.1
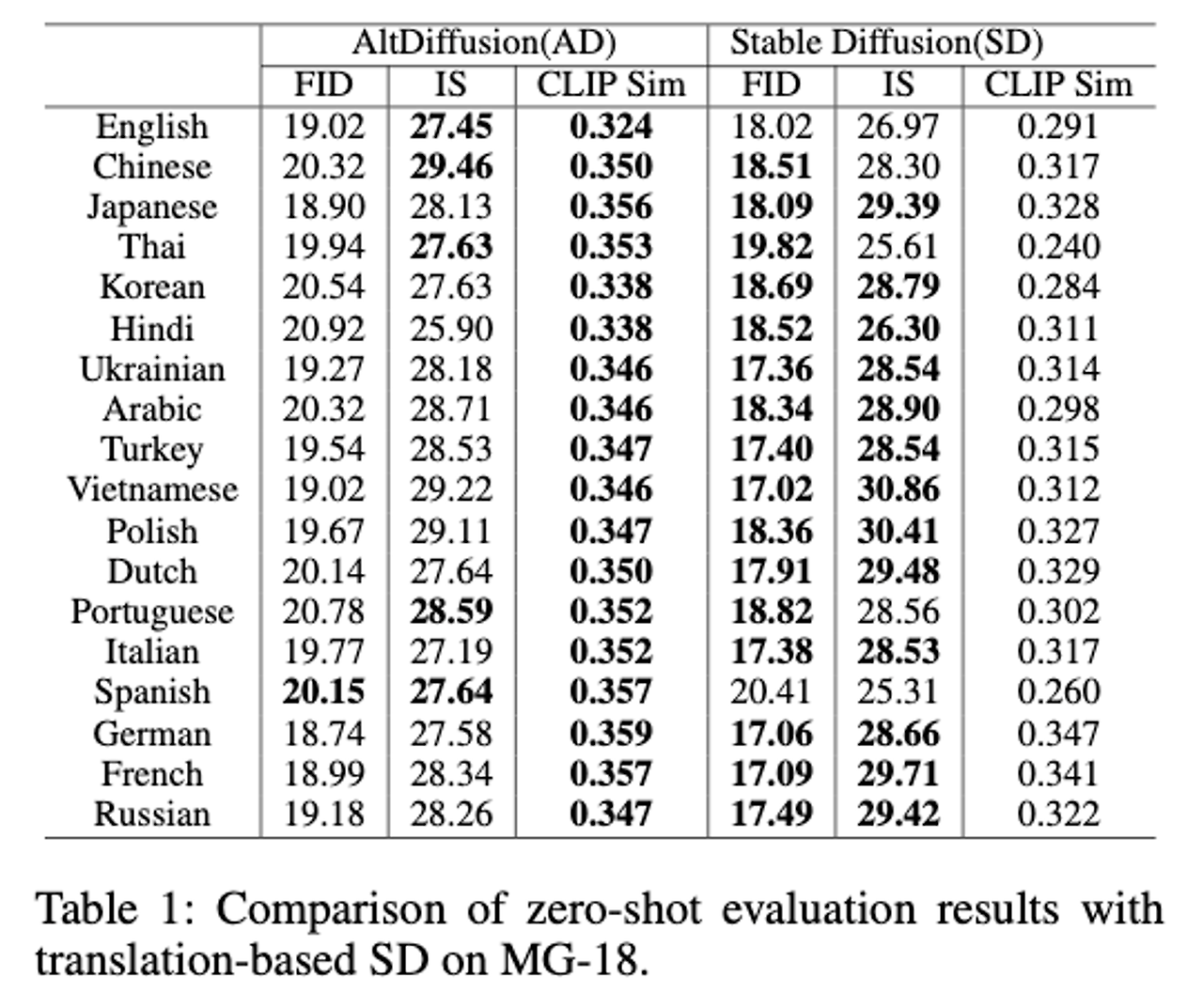
- NLLB-3B를 사용하여 번역함
- AD가 모든 언어의 CLIP SIM에서 SD를 능가하고 FID, IS도 비슷한 성능을 보여줌
Compare with Other Baselines
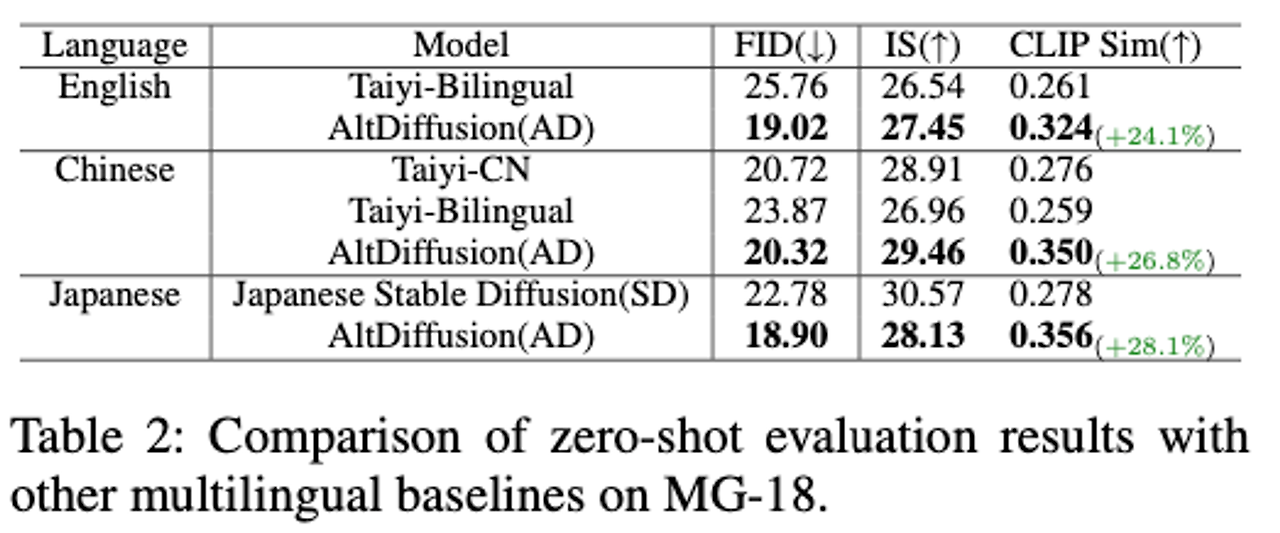
- Taiyi Chi- nese, Taiyi Bilingual ,and Japanese SD등의 다른 다국어 diffusion 모델과 비교했을때도 좋은 성능을 보여줌

- AD로 생성한 이미지 Figure인데, 다양한 언어 프롬프트로도 이미지를 잘 생성해내는 모습을 볼 수 있음

다른 다국어 언어모델과 비교해서 언어를 더 잘 이해하고 그에 맞는 이미지를 생성해내는 모습을 볼 수 있다. 위 그림을 보면 AD에 비해 다른 언어 생성 모델들은 어떤 다국어 text를 무시하거나 실수해버리는 경우가 발생했다.
Results on MC-18
문화적인 개념에 대한 모델의 이해 능력 평가를 human evaluation으로 실시했다.
평가 세팅
- 각 언어별로 3명의 annotator를 부여함
- 같은 프롬프트로 AD, SD에서 각각 생성한 이미지를(각각 1장씩 총 2장) 보여줌
- Culture Consistency, image-Text Consistency를 기준으로 각각 1-5점의 점수를 부여함
- 점수 매긴 후 최종적으로 [“Alt is bet- ter”, “SD is better”, “Same”]를 선택함. 여기서 선택한 값은 각각 아래의 식중 |A| , |B| , |C| 에 해당함

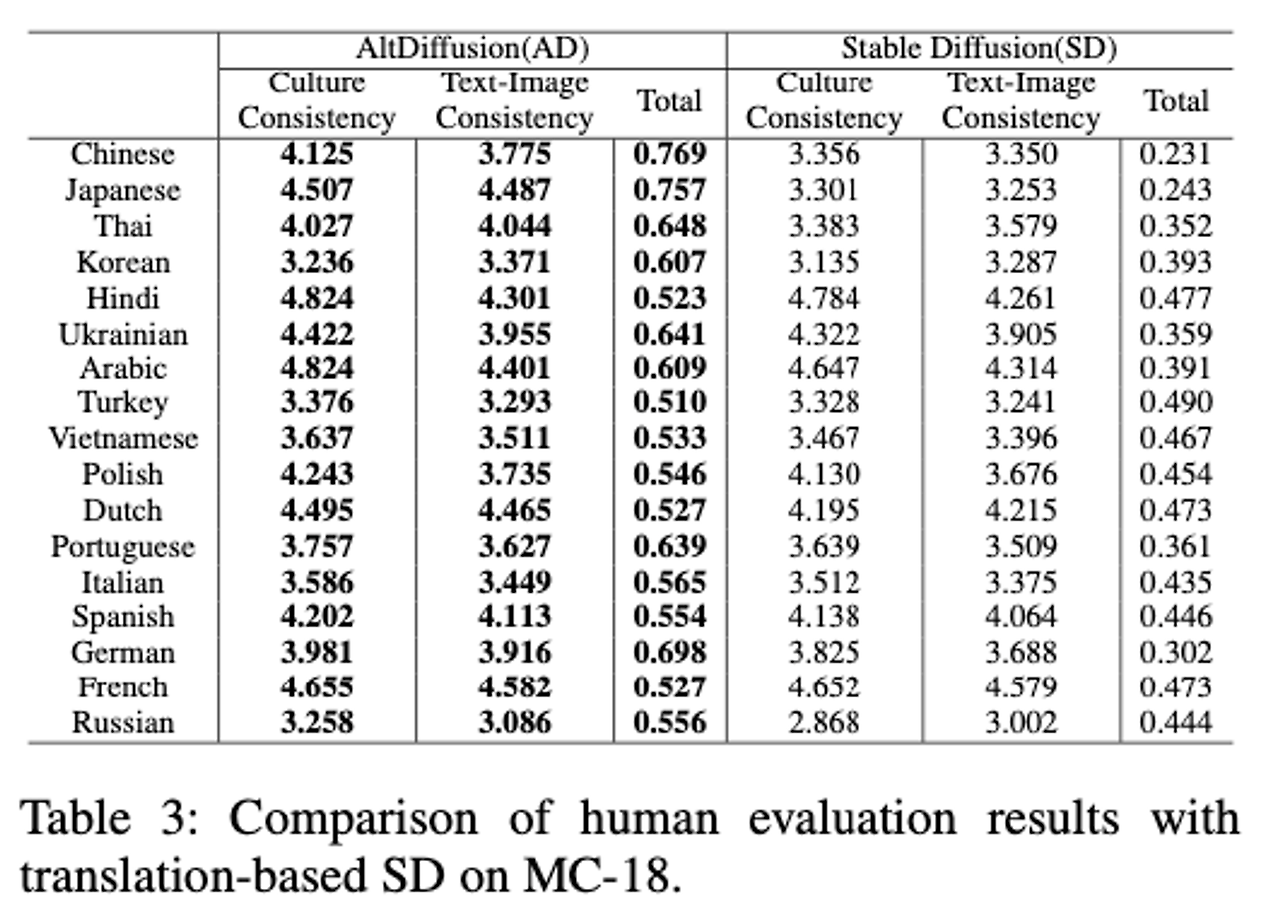
- 결과를 보면 AD가 SD에 비해 뛰어난 점수를 가진다. 이 말은, 기존 Stable Diffusion보다 언어의 문화적인 개념을 더 잘 이해하여 이미지를 생성한다고 볼 수 있다.

위 그림에서 (a)는 중국의 시를 프롬프트로 넣은 것인데 SD에서는 사실적인 이미지를 생성하고 있는 것을 보인다고 한다 라고 논문에서 표현하고 있는데, 보면 확실히 바람이 불고있다는 텍스트적인 의미를 AD가 조금 더 잘 이해하고 있는 것으로 보인다. (b)에서는 중국의 유명 화가인 Daqian Zhang이 그린 그림을 그려달라고 요구했는데, AD가 더 잘 반영하고 있다고 한다.
Conclusion
맨 처음 가졌던 의문점, key point에 대한 해답을 정리하며 글을 마무리 하려 한다.
- 왜 Multilingual Diffusion Model이 연구되었는가? (번역툴을 이용하는 영어 기반 Diffusion Model과의 차별점)
- Multilingual Diffusion Model의 핵심은 다른 언어의 culture, identity, unique한 표현도 모델이 이해해서 이미지를 생성하길 원하는 것이라 생각한다. 번역만으로는 그 언어에 대한 문화적 요소들 모두를 이해하기에는 한계가 있다고 한다.
- CLIP Text Encoder 부분만 학습을 시키는가, 이미지에도 Culture domain을 반영하여 학습시키는가?
- 본 논문에서는 1차적으로 Knowledge Distillation기반으로 다국어 데이터셋을 이용해 Text Encoder를 학습한 뒤, 다국어의 이미지 데이터셋을 이용하여 Dfiffusion도 학습한다. 따라서 질문에 대한 대답은 텍스트뿐만 아니라, 이미지에도 다국어 학습이 일어나고 있다. 처음에는 LAION이라는 데이터셋이 그저 다국어 코퍼스로 이루어진 대용량 이미지 데이터셋이기때문에, 그 언어에 대한 직접적인 문화적인 요소를 담고있다고 보기는 힘들것 같다고 생각했는데, 만약 데이터셋에 특정 언어, 문화에 대한 이미지를 가지고 있을 경우에는 일부 반영 될 것으로 예상된다. LAION 데이터셋에 한국어 subset만 몇개 보더라도 한복, 태극기등의 문화적 요소 데이터들이 담겨있기 때문에 문화적 요소를 학습시켰다고 말 할 수 있을것 같다.
- 실험 또는 성능 평가를 어떻게 했는가?
- 자체적으로 제작한 두개의 벤치마크 MG-18, MC-18로 실험을 진행했다. 본문 참조.
- Limitation
- 본 논문에서는 언급하고 있지 않았다.
- 모델 인퍼런스 후, 찾아볼 예정이다.
'논문리뷰' 카테고리의 다른 글
| [QLORA] QLORA: Efficient Finetuning of Quantized LLMs (1) | 2024.04.15 |
|---|